Other than that failed attempt at a bugfix, I did not contribute any Greenstone work for the overall community of GS users this week. Some work from back in June is worth writing up though.
Greenstone plugins often use existing open-source software to process complex document types like PDFs and older versions of Word documents, to get them to be searchable in the built collection. However, for Greenstone to be able to process newer Word documents, that have the docx file extension, users so far needed to have either the free LibreOffice or payware Microsoft Word of the Office Suite installed. LibreOffice is large in size and sometimes it can be hard to get it to successfully run headless or to restart it in headless mode. After I saw some messages in the mailing list about this, I searched online for if new command line tools had appeared in the meantime that could convert docx files to html or text. Because then Greenstone’s existing UnknownConverterPlugin can be used to run that command line tool to extract text from docx files, so that they’ll get indexed and become searchable in the built collection.
To gain a better understanding of generally using the UnknownConverterPlugin, refer to the tutorial at http://files.greenstone.org/tutorial/gs3-current/en/unknown_converter_plugin.htm
Apache Tika is Apache’s open-source software to extract text from countless different (textual) document types, one of which is docx. While one can write code to make calls on Apache-Tika’s API, their ready made jar file contained everything that we needed to get Greenstone to index text in docx files.
All I had to do was configure the UnknownConverterPlugin to make use of the Apache-Tika jar dropped into GS3’s extension folder, such that docx files could be processed and indexed (for searchability) by Greenstone without requiring users to install libreoffice.
The UnknownConverterPlugin has been officially available since Greenstone 3.09, so that 3.09 users can also start using Tika with the plugin, by
1. creating a subfolder called “tika” inside their GS3-install-dir/gs2build/ext,
2. downloading the Apache-Tika binary jar file from https://www.apache.org/dyn/closer.cgi/tika/tika-app-1.24.1.jar (or by visiting http://trac.greenstone.org/browser/main/trunk/greenstone2/ext/tika/tika-app-1.24.1.jar and clicking the link labelled “downloading” there), then dropping the downloaded jar file into GS3/gs2build/ext/tika
3. and then configuring an UnknownConverterPlugin instance for any collection that needs docx processing as follows:
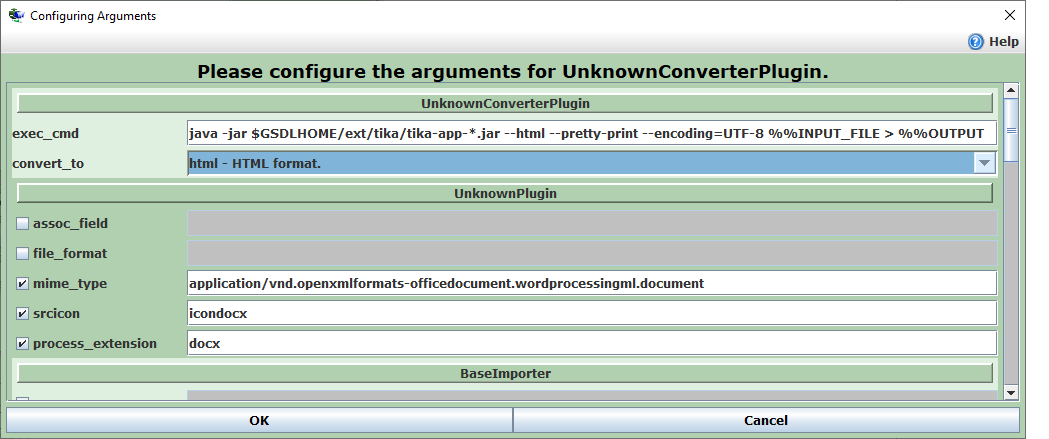
All 3 of the above steps are already setup for you in the GS3 binaries generated every night and available from http://www.greenstone.org/caveat-emptor/
Untried: Greenstone 2 users can try a grabbing a nightly GS2 binary from http://www.greenstone.org/caveat-emptor/ as it should also come with an UnknownConverterPlugin). The nightly GS2 binaries should already have an ext/tika subfolder within the GS2-installation folder, containing the tika jar file. Otherwise you can create this folder yourself and download the tika jar file into that location as in step 2. Next configure your UnknownConverterPlugin as in step 3 above before building your GS2 collection containing docx files.
You’re not limited to processing docx files by using UnknownConverterPlugin with Tika. You can process other textual doc types, whether already supported by existing Greenstone plugins or not, by configuring a new instance of UnknownConverterPlugin and setting the mime_type, srcicon, process_extension (and file_format) fields appropriately for that doctype.
The above instructions on using the UnknownConverterPlugin has now also been added to the Greenstone wiki, so you don’t have to track down this blog page if you want to revisit the instructions of using Tika with the UnknownConverterPlugin. Simply search the Greenstone wiki at wiki.greenstone.org for “UnknownConverterPlugin” or “Tika”.
]]>